Harnessing the power of the intelligent edge
Over the past 10 years we’ve watched cloud computing come of age as more companies send their data to the cloud for processing, storage and management, rather than keeping that data on a local server or edge gateway. The benefits of cloud computing are vast, however there is another key development on the horizon as the IoT matures: edge computing.
Edge computing takes some of the essential data-processing and analytics work from the cloud and brings it to edge devices—not replacing cloud computing, but complementing the solution. Gartner predicts that while currently only 10 percent of enterprise-generated data is processed at the edge, by 2022 that figure will reach 50 percent. Half of all processing power is expected to slowly shift from the cloud to edge devices, leading to IoT projects that utilize the power of both cloud computing and the intelligent edge to make smart business decisions.
The benefits of cloud computing are vast, however there is another key development on the horizon as the IoT matures: edge computing.
The need for data from the intelligent edge
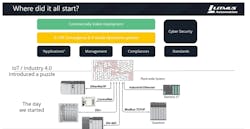
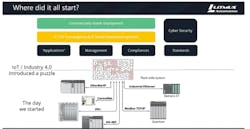
Several trends indicate that we’ll all be increasingly harnessing the power of the intelligent edge. First, the onset of Industry 4.0 brought about the fundamental need in the industrial market for an IT/OT converged ecosystem. Success of projects is less about merely collecting vast amounts of data; success instead depends on properly analyzing that data and creating value. As shown in the figure below, Industry 4.0 has created new requirements for managing disparate devices and legacy systems, implementing compliance and standards, security and test practices.
Artificial intelligence, or machine learning, is another key technology driver for edge computing. Machine-learning optimizes performance by quickly processing large, interconnected data sets. Depending on the application, the system is much more efficient at the edge than in the cloud. For instance, consider an AI-enabled manufacturing robot that moves parts across the factory floor. If machine learning happened in the cloud, processing delays could cause safety or performance issues. In order to allow the autonomous vehicle to make decisions on the fly, data-processing must happen at the edge.
Edge computing uses cases range from residential applications (Nest thermostats) to simple manufacturing projects to larger smart city or extended macro-level initiatives. The fundamental goal for all of these edge-computing projects is collecting data from a large amount of industrial assets, then putting that data to use immediately. The assets may be robotic systems, controllers, PLCs or many other devices. Some of these devices are already IoT-ready, while others were never designed for these types of uses. The common thread is the challenge of gathering data from those disparate devices, then processing, analyzing and acting on the data right at the edge of the network or device.
Industrial use case: Making use of data at the edge
15 years ago, merely collecting data was the main concern. Now the priority is taking action with data as you collect it. The easiest way to accomplish this is with an edge-computing platform that can discover all of the devices on the network, identify them, and start collecting data within a few minutes. The platform standardizes data, then runs application on top for further processing. Edge devices have a constrained environment—they have a small amount of resources—yet they need to run complicated analytics applications. An edge-computing platform is the framework for multiple applications to utilize the data in an efficient manner.
Consider this example: a multinational beverage company has plants that were designed 60 years ago. Automation systems were introduced over time and some mission-critical elements were added. Some of the vendors are no longer in business, and the components (obviously) did not have edge-computing capabilities baked in. Take one asset in particular—a boiler. Production-line anomalies caused by old machine systems are requiring long-term and costly maintenance. The brewing process halts for several hours when malfunctions occur on the old machines, and the instantaneous cost of failure is $6,000 per hour.
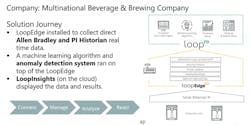
In order to avoid downtime, the beverage company adopts an edge-computing platform solution that includes four key steps: connect, manage, analyze, react. The platform collects real-time data. A machine-learning algorithm and model of normal behavior is created and an anomaly-detection system runs on top of the platform. Each edge device can detect anomalies and predict pre-determined variables.
An IoT platform connected the data to the cloud and a live dashboard for complex IoT analytics and visualization displayed the data and results. The end result was, within two months, the plant manager could receive failure predictions nine hours in advance. Maintenance alerts were generated and a backup system was arranged.
So what does this all mean?
The use case points out the need for a proper edge-computing framework. A framework helps companies get more out of their edge-computing hardware. The right framework enables the development of more applications on top of the same edge-computing system, the ability to scale the solution, and the capacity to take one small piece of hardware and extend it to multiple applications.
In the end, this combination of edge computing and cloud computing power enables industrial customers to implement next-generation IoT solutions that efficiently collect a lot of data, and process it immediately for better business decisions.
