Getting resourceful with machine learning
By Pravin Dagdee, Prodapt head of infrastructure management services, Jagadeesh Bhavanasi, data architect, and Vishwa Nigam, manager of business analytics & insights
Event flapping is one of the major challenges faced in IT/telecommunications-infrastructure-monitoring. From the data-center perspective, flapping events are those that occur when a service or host starts changing its state too frequently. This results in a large number of alarms, which can indicate either transient or real network problems. Some of the reasons for flapping events to occur are hardware/software errors, storage issues, unreliable connections and broken communication links.
Event flapping causes resource wastage, decreased performance, and diminished customer experience. We estimate that 50% of the tickets raised during monitoring are “flapping events.” It is therefore important to formulate an effective strategy to reduce these events.
Below are the three common approaches to prevent frequent flapping events.
1. Reactive Approach: Addressing flapping events as they occur
Following are the steps required to address an event and take the system back to normal.
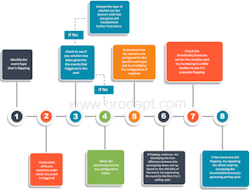
As the name implies, teams react to the event once it occurs. Irrespective of a flapping event or normal event, there will always be a resource allocated to troubleshoot and resolve the issue. This consumes employee time and in some cases, results in service loss.
2. Proactive approach: Update/reset the thresholds to reduce the volume of flapping events
Setting thresholds that are too low can cause unnecessary event triggers in huge numbers. One of the ways to resolve this issue is by setting a higher threshold to eliminate these events.

Identifying the events’ behavior and proactively increasing threshold limits for those events can significantly reduce the number of flapping events. This reduces resource wastage, as monitoring teams get fewer flapping events. However, setting a higher threshold may affect the visibility of genuine events and result in service loss.
3. Predictive approach: Predicting and categorizing flapping events to minimize resource wastage and service loss
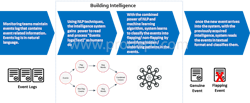
Data centers can efficiently manage flapping events by reducing employee time and service loss through predictive approach. Machine learning can be used to execute this approach effectively.
Machine learning-based solution to predict flapping events:
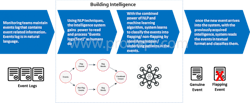
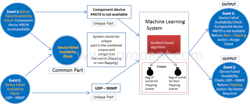
The below infographic demonstrates how big data frameworks help in gathering and feeding huge volumes of data into the machine learning system:
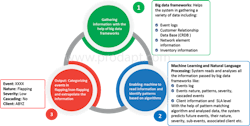
Use case: How machine learning analyzes and categorizes the nature of events in data centers.
Machine learning helps data centers to identify and categorize events using big data frameworks, which reduces resource wastage by 50% and service loss by 10%.
-
Objective: Identifying and categorizing flapping events by leveraging machine learning and natural language processing (NLP).
-
Machine learning algorithm used: Gradient Boosting Machine
-
Event type: Device failed availability check; a component device is not available