Feeding contextualized data to cloud services with MQTT Sparkplug
One of the biggest pain points for any company working to digitally transform is feeding big data and enterprise applications with usable and contextual OT data. There are a lot of great cloud and enterprise platforms out there that provide companies with the insights they need to improve operations—they just need the data.
Companies face several roadblocks in getting the data upstream—including a large variety of proprietary data types, security concerns, a lack of data standardization across factories, a varied knowledge base at each site, and no standard bridge to move data from OT to IT systems.
The end goal is to provide data to cloud services in the following ways:
- Standardized so it can be quickly and easily ingested not just by one application but by many.
- Secure so cloud applications don’t have direct access or control over the OT plant floor.
- Templatized and contextualized so the information can be used at multiple factories regardless of equipment type.
- Scalable with an easy, repeatable process that requires no coding and continually feeds data to any application.
Bridging data from OT to IT often requires a lot of custom code and special expertise, the process is not scalable, and creates a laundry list of proprietary-protocol issues. As a result, many companies collect and store a great deal of data but analyze only a fraction in the cloud.
Enter MQTT Sparkplug, an open-source software specification that enables the normalization of data at the edge, from the shop floor to any cloud or enterprise application. MQTT Sparkplug has emerged as the ideal protocol for feeding contextualized data-to-cloud services for machine learning and other applications for several reasons.
Using MQTT Sparkplug to send OT data to cloud systems
First, a quick summary of MQTT. MQTT is the dominant messaging protocol for ingesting edge data-to-cloud services because it is a lightweight, publish-subscribe, message-oriented middleware that allows for multiple data consumers. MQTT is simple, efficient, and open standard, enabling companies to gain access to more data and then share it across IT systems.
MQTT Sparkplug, more specifically, provides a solution to feed data to cloud systems in a way that satisfies all the requirements—standardized, secure, templatized and scalable. MQTT Sparkplug is open standard as part of the Eclipse Tahu project, and provides applications with a framework to integrate data.
Let’s look at how MQTT Sparkplug satisfies each requirement for feeding data-to-cloud services.
Standardized
Sparkplug takes the OT data and defines how to publish and represent it, so any subscriber, any machine learning or AI application knows what it is and how to utilize the data to create data models without any programming or coding. Sparkplug establishes a single source of truth for models, assets, and tags at the edge, taking OT data from various sources and protocols and defining it for IT (Figure 1). OT data is converted to IT data, then put in a standard interface for big data, which leads to scalable data insights and business improvements.
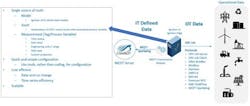
Figure 1: MQTT Sparkplug standardizes data so it can be easily shared from the shop floor to the cloud.
Secure
MQTT Sparkplug pushes the data upstream while isolating systems and providing security at every step from OT to IT. Data is remote originated, outbound, and encrypted with TLS. Only approved consumers can subscribe to specific data that can be read and ingest-only, and the data is self-discoverable so changes are pushed up as well. MQTT allows OT to share data with those machine-learning applications without letting them come in and connect to their systems or do any remote control that opens security concerns.
Templatized
The only way to scale the movement of OT data to the cloud across multiple lines and sites is with an easy, repeatable, templatized solution. Templates are the key to doing analytics in a timely manner in a cost-effective way. Sparkplug builds templates that are models of the asset—such as a CNC machine or a motor—providing the right contextual information with a set of tags so the model can be utilized by any cloud system and at multiple factories, regardless of the equipment there. Any cloud application can quickly utilize the data off-the-shelf and perform analytics without having to write special code or transform the information.
Scalable
Many data ingestion solutions are written with custom code to manipulate the data so it can be consumed by IT, but that only works for a one-off case with zero scalability. It is hard to maintain across multiple factories where things are changing all the time, devices are being added, and data consumers are also evolving. With Sparkplug, factories have one open methodology where multiple products support the protocol and templates can be defined and configured on the fly. New devices or factories can be added rapidly with self-learning and auto-discovery.
Conclusion
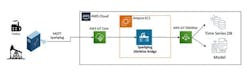
Consider a cloud platform like AWS Sitewise or Microsoft Azure Digital Twin. With an industrial IoT platform in place that enables MQTT Sparkplug standard connectivity as shown in Figure 2, the data can be quickly adopted and sent to the cloud platforms for further analytics and to drive the development of machine learning models.
Previously, MQTT Sparkplug was primarily a play on the factory floor, but now it takes OT data and points it to IT systems quickly and easily with an open-standard approach. Use cases ranging from OEE to AI can be enabled with MQTT Sparkplug in a way that is secure and repeatable, requiring no coding.
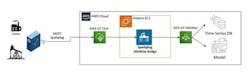
Figure 2: MQTT Sparkplug is the bridge from OT data to IT cloud and enterprise systems.
Arlen Nipper is president and CTO of Cirrus Link
